Wikipedia is the 800 lb gorilla in the Google search results. It ranks for almost half of all searches. It is the online resource. Google has even built large portions of its Knowledge Graph off the back of Wikipedia.
It’s also a motherlode of SEO resources – right behind Google Keyword Planner, Google Search, and Google Analytics. It’s useful for both on-page & off-page SEO for 2 reasons –
- Wikipedia is human knowledge. It uses language the way humans use it, because it’s written by humans. It connects topics and keywords in ways that only humans can.
- Wikipedia is the online resource. People trust it, use it, and reference it.
So whether you are just starting out planning your website’s keyword strategy, looking for new content ideas, or looking for ways to build trust for your website, here’s how to use Wikipedia for SEO and content marketing.
How to Use Wikipedia for Off Page SEO
A core part of Google’s algorithm uses links from trusted websites to gauge the trust & relevance of other websites (ie, “off-page SEO). And Wikipedia is the trusted, relevant resource. For a while getting links from Wikipedia began to generate a lot of spam.
In 2007, Wikipedia implemented on all outbound links, which means links from Wikipedia do not pass PageRank or anchor text (ie, Wikipedia articles do not directly help webpages in the eyes of the Googlebot).
For SEOs who have a formulaic outlook on SEO (ie, links + keywords = rankings), this change made Wikipedia a lot less appealing for link building and off page SEO in general for both spammers and non-spammers alike.
Google says that “In general, we don’t follow them [nofollow links].” Many times, SEOs generally divide into 2 camps. The first group says “well, nothing worthwhile here for good links…let’s move along to the next tactic.” The second group focuses on the “In general,” forms a conspiracy theory, and comes up with ever more creative ways to spam Wikipedia (the same folks who spam blog comments).
Wikipedia’s editors do not take kindly to spam or using Wikipedia for commercial gain. So even if you are able to get a link placed in Wikipedia, you are likely to incur the private (or public) shaming…or at least a citation that doesn’t look good for your brand.
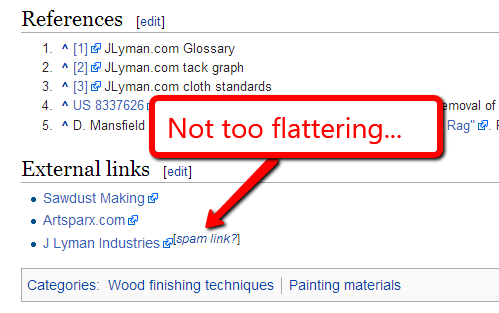
However, there are legitimate ways to use Wikipedia to earn links that are wins for everyone involved.
1. Grab broken links & citation needed links
October 2018 Update – This tactic is still worthwhile, however, you are going to have to *start* with the information below, and build on it. Archive.org partnered with Wikipedia to automatically rescue broken links on Wikipedia. That is super-useful, and it’s a long time in coming.
However, the point remains that these links are still not pointing to the freshest, most up to date sources. They are still there, but you may have to route your sleuthing via Archive.org to find the original broken URL.
Just because Wikipedia links are nofollow, doesn’t mean they aren’t valuable. Wikipedia links can get you referral traffic (ie, people clicking your link). Plus, the same people who click Wikipedia links are likely to link back to you on their site, since you are after all, a Wikipedia reference.
The key is to get a Wikipedia link without getting called out for commercial spam – actually be helpful and improve Wikipedia instead of treating it like a graffiti board. Normally, it would be a tough job finding appropriate places to place a link, except that Wikipedia’s editors have done the work for you.
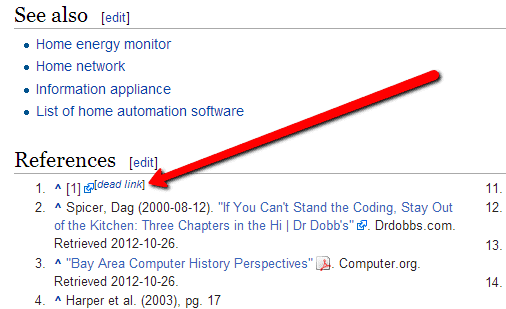
Do a Google search for:
site:wikipedia.org [keyword] intext:“dead link” (or “citation needed”)
If you just want to browse all the pages with broken links – Wikipedia has a resource for you here. WikiGrabber is also a cool tool to help narrow your search.
Do you have a resource (or can you create one) that provides a reference for that missing or dead citation?
If you do, grab that link! You’ll get the referral traffic, and a nofollow link from the most trusted website on the Internet, which I’d value more than any unseen, unclicked dofollow link any day.
But remember that you really have two similar, but slightly different options here.
If you are looking at a Dead Citation – then you are basically doing broken link building with Wikipedia. You can look at the old piece of content on the Wayback Machine and recreate it with your own spin (ie, not plagiarized) on your own website and claim the link*
*the alternative, gray-ish hat version is to head to a good domain registrar and try to buy the expired domain, rebuild it, but include links to your site.
It’s how a lot of shady SEOs build “private blog networks” with tons of expired domains. But building one to a few is a solid tactic.
If you are looking at a Citation Needed link – then you’ll need to create content that meets the needs of the citation. It’ll require a bit more research and planning – but not as much as an open-ended piece of content.
Plus, you’ll have a guaranteed link opportunity. Credibility is critical. You’ll need to find an expert or real data that will provide an actual citation. If you can’t do that, then stick with dead links.
But don’t stop with your Wikipedia link! You can also place that dead link into a link explorer like LinkMiner or SEMrush. Find all the pages that used to link to the same resource, and reach out to them.
2. Look for link opportunities with topic pages
Wikipedia pages rank for half of all searches, which creates a feedback loop. Wikipedia pages rank so well because people link to them. They continue to rank even better for a wider range of searches because high ranking pages get more links.
When a journalist needs to cite a quick definition or a blogger needs to link to a concept, they do a quick search, and link to the relevant Wikipedia page.
Wikipedia pages often are the most relevant page for broad keywords. People link to them more often than not. And you can use that to find people who’d be interested in linking to you.
Take various Wikipedia pages relevant to your market. Head over to LinkMiner or SEMrush, or other and drop a relevant Wikipedia page in. See who is linking to that page.
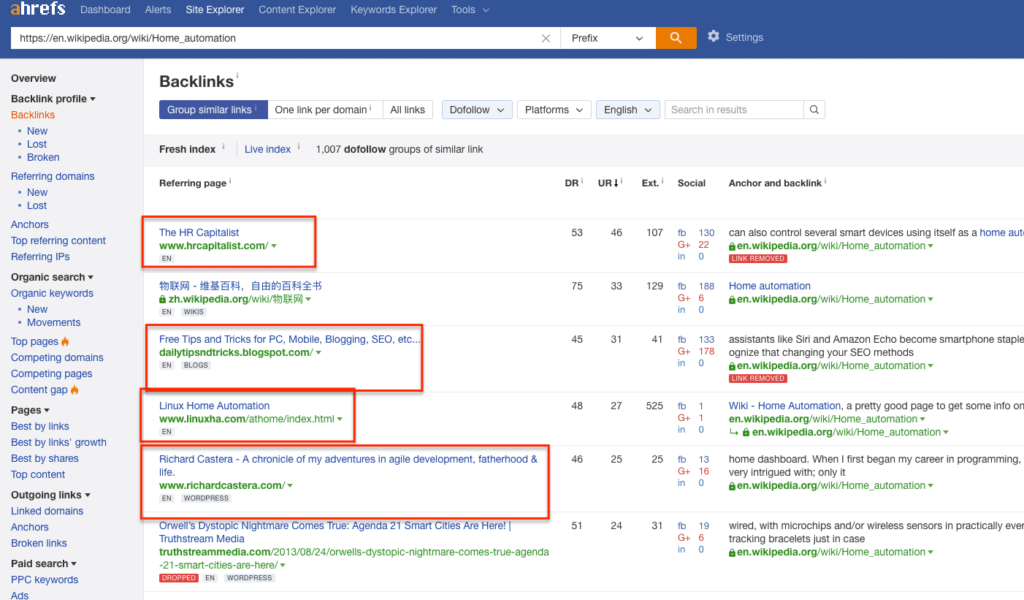
You’ll find a list of people, sites & blogs who would be relevant to your site & your readers – and may very well link to your content.
3. Look for link opportunities with reference pages
Even in the early 2000s when I was in school, I heard the saying “don’t cite Wikipedia, but use Wikipedia to find citations.” In other words, when people are doing research they start with Wikipedia to find trusted resources (note how this relates to #1).
And, if they are doing research for their site, they’ll link to those resource pages (again, a reason for doing #1), since the human editors of Wikipedia have found those reference pages to be the most relevant citations.
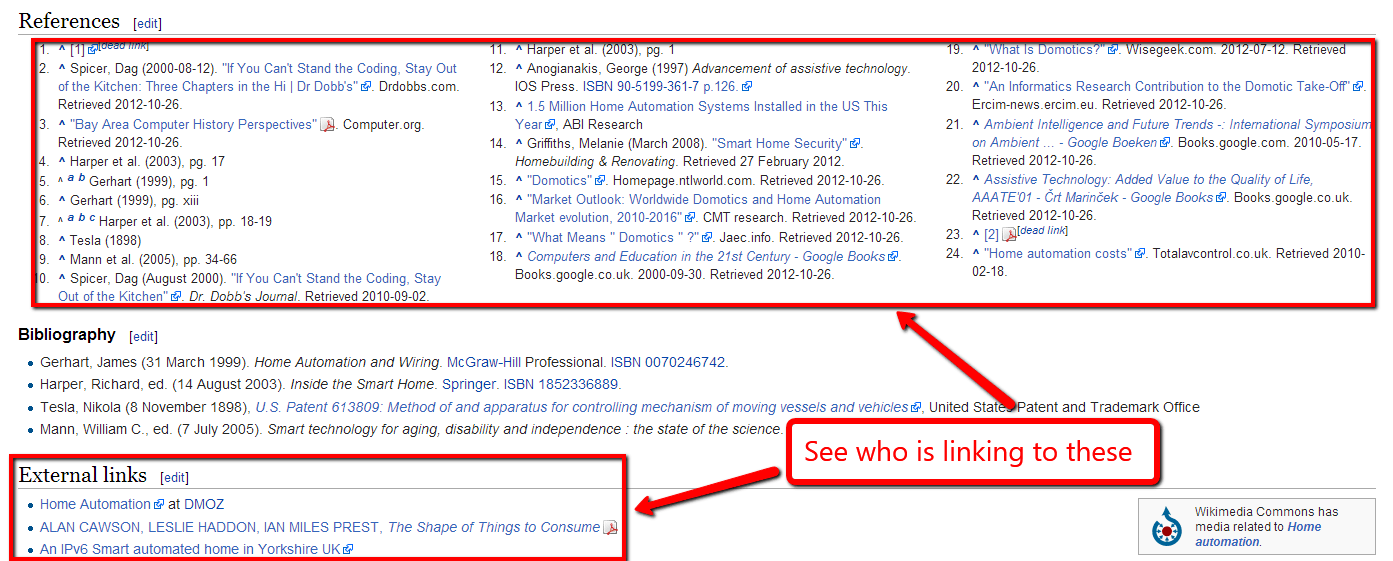
Take all the URLs of all the citations in a relevant Wikipedia article and plug them into SEMrush / Ahrefs. You now have an even bigger list of websites, people, and blogs who might be interested in linking to your content.
4. Create Your Own Wikipedia Page
In the original version of this post, I deliberately left this point out.
Why?
Because I disdain spam, especially on a wonderful, public resource like Wikipedia.
But here’s the thing. If your organization deserves a Wikipedia page, then you should have one, and it should be structured well.
Google and many other data sources will use it, so it might as well be right. Do your research into Wikipedia’s guidelines, and work with an experienced Wikipedia editor to upload and edit it.
How To Use Wikipedia for On Page SEO
Whether you are planning a content or keyword strategy, nothing beats real data from humans who either deeply understand or have real questions about your topic. Understanding the language, questions, and interest of your audience is key to a successful SEO campaign.
The tough part is the getting a solid, accurate start on a strategy. You could start by taking educated guesses or doing extensive customer interviews.
Or you can lean on the human-edited encyclopedia that ranks for nearly every conceivable topic.
1. Gauge Interest for Topics
Search volume is a key component of SEO research. But with Google’s moves away from both phrase match in Keyword Planner and their focus on topics not keywords, it can be tough to gauge exactly how much interest is out there for any given piece of content.
The good news is that Wikipedia probably already ranks for many of the keywords relevant to a given topic, and you can find out how much traffic that article gets. All of Wikipedia’s traffic stats are public, but Domas Mituzas has published a tool that makes the research really easy.
Head over to http://stats.grok.se/. Enter your Wikipedia article. Get traffic numbers every month back to 2007.
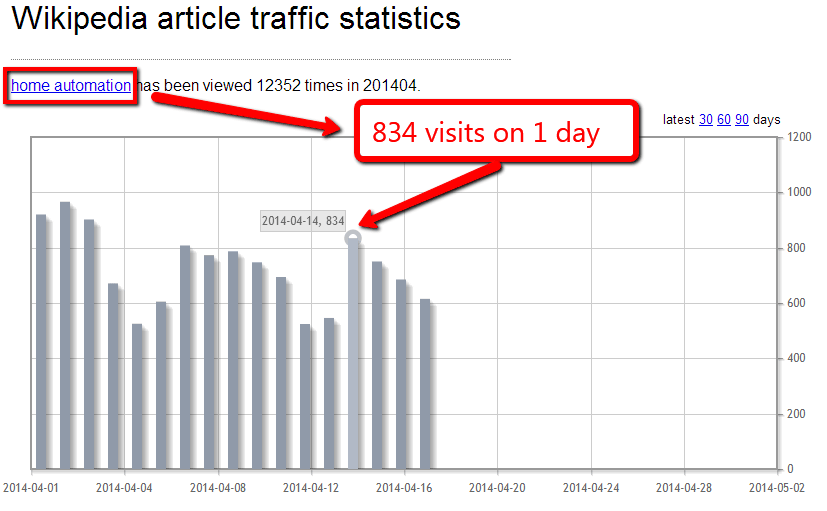
If a well-edited Wikipedia page is only getting a few visits a month – you’re probably barking up the wrong content marketing tree. If it’s getting solid, consistent traffic, the you have something to build towards.
Otherwise, taking this data and pairing it with Google Trends and Keyword Planner will give you solid insight to the traffic potential of new content.
2. Do Keyword Research with Wikipedia + Keyword Planner
The keyword strategy portion of SEO is all about figuring out both what language your audience uses to describe your products/services/content and figuring out how search engines understand that same language.
Whether you are working for a client in an unfamiliar industry or building your own content that needs to speak to your audience, the human aspect of keyword research is often the toughest.
Too often, SEOs will outsource the heavy initial brainstorming to…a machine. Also known as the Keyword Planner. The problem with Keyword Planner is that it’s only as good as the initial human inputted keywords.
If those initial keywords aren’t a good sample, then you’ll keep following a rabbit trail further away from the right keyword strategy.
This circles back to the original problem of finding a solid initial list of keywords from a human brain that understands your topic.
Enter Wikipedia – again, a resource written, edited and read by topic experts & your audience. (h/t to Dan Shure on this original idea – see his original post here)
Take a relevant Wikipedia page URL. Go to Google Ads –> Keyword Planner.
Head over to New Keyword Ideas. Drop the Wikipedia URL into the Landing Page field.
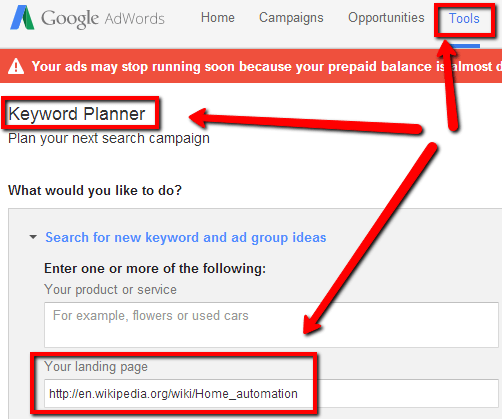
Out will come a solid seed keyword list that you can use to expand & refine your keyword list.
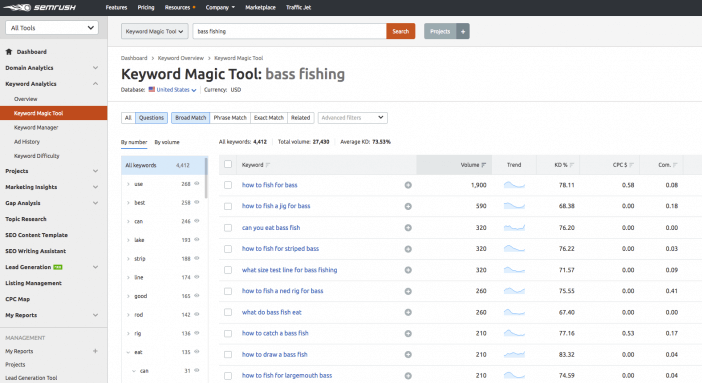
Google Ads is really cracking down on research via Keyword Planner, but you can do something similar with a tool like SEMrush or SiteProfiler.
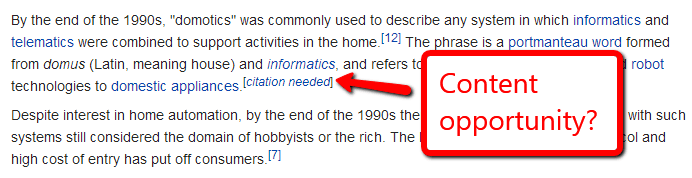
3. Plan Content via dead links, citation needed & stub pages
I’ve already mentioned this idea to grab links – but [citation needed] on Wikipedia also represents a particular content opportunity. It’s a direct signal Wikipedia needs content to back up a claim.
Just like how the appearance of mirriam-webster, answers.com, a PDF file, or a forum post (all generally low quality results) in the top 10 of search results represents a bat signal that Google wants better content – a [citation needed], [dead link], or stub page means that there are literally no trustworthy immediately available options.
Anyone who builds the content to fill that need is positioned not only as an authority – but also set up well for the benefits of off-page idea #1.
Plus, you can often take a bit of a shortcut building this content and doing outreach. For dead links specifically, you can take the (now dead) URL, head over to the Internet Archive Wayback Machine, and look to see what the linked-to resource used to look like. Build something better, then reach out to everyone else who linked to the old page.
For example, remember that dead link I pointed out earlier in off-page idea #1? Check it out in the Internet Archive…
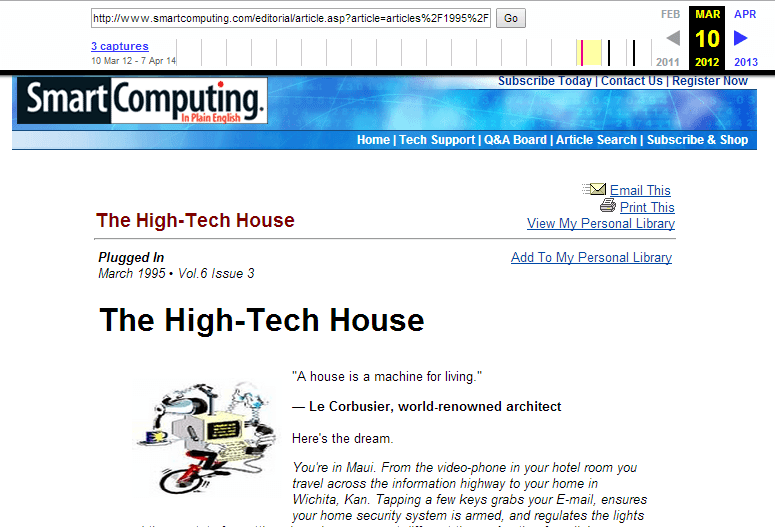
I now know exactly what type of content served as a reference. I can rebuild even better and get the Wikipedia link…along with any other sites that used to link to the broken page.
4. Plan Content around the reference pages
This specific idea comes via Brian Dean’s guest post at OkDork. Not only are reference pages at the bottom of Wikipedia articles great for spotting link opportunities – they are also useful for generating content ideas.
After all those pieces of content were good enough to be found & cited by a Wikipedian, what if you could make it even better?
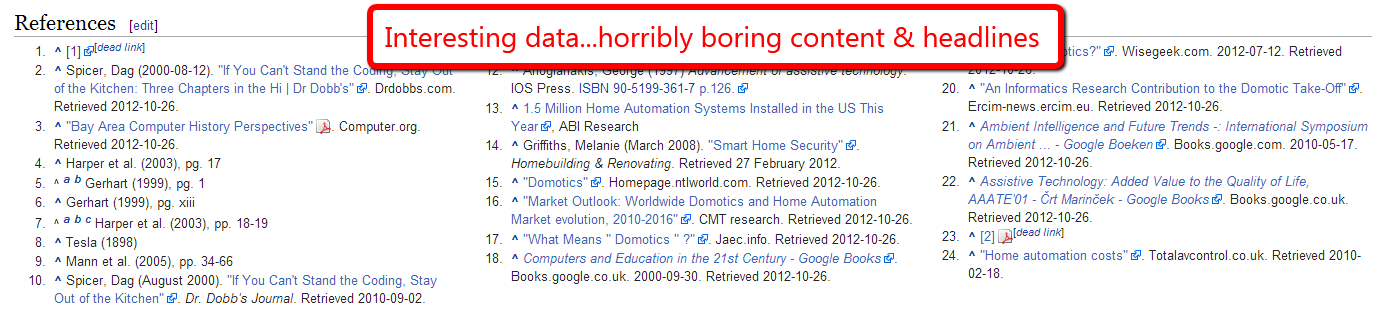
What are themes and common questions that appear in the reference pages? Is there any interesting data? Can you repackage the data into interesting content?
Next Steps
Using Wikipedia isn’t a shortcut to building your site’s SEO or content strategy. It’s not a place to spam. But it’s also not a place to ignore.
It is an amazing resource that you can use to build your own site, while contributing back to Wikipedia. Your next step should be to make a short list of Wikipedia pages relevant to your audience & topic.
Go sign up for a free trial at SEMrush (most data) or SiteProfiler (budget but good).
Then use them for keyword research; use them for off-page research; improve the Wikipedia pages – and improve your own site.
EDIT 9/4/14 – GrowthAddict came out with a new tool called WikiGrabber, which can quickly find some of the dead link & citation needed opportunities. Be sure to check it out.
EDIT 5/20/14 – The New Yorker ran a fascinating piece on how edits become truth on Wikipedia – very relevant to branding. Read it here.
Found this useful? Then go donate to the WikiMedia Foundation.
Be sure to explore the full list of Free Tools To Find Prequalified Content Ideas!




This is awesome! I never would have thought about some of these techniques. You SEOs really are MacGyvers.
Hi Larry,
Hat tip – this is now added to my bookmarks! This may prove an invaluable avenue for some of my clients.
Many thanks,
Eddie
Nice article – I usually don’t leave comments, but holy shit there’s a lot of garbage SEO blogs out there so it’s nice to see someone actually providing useful information.